CPU의 종류에 따라 메모리에 바이트를 저장하는 순서가 달라진다.
Little Endian은 우리가 주로 사용하는 Intel, ARM CPU방식이다. 바이트의 순서를 정할때 큰자리의 비트가 뒤쪽부터 채워지게 된다.
그에 반에 Big Endian은 IBM, 모토로라에서 사용되며 바이트의 순서는 큰자리의 비트가 앞쪽부터 채워진다.
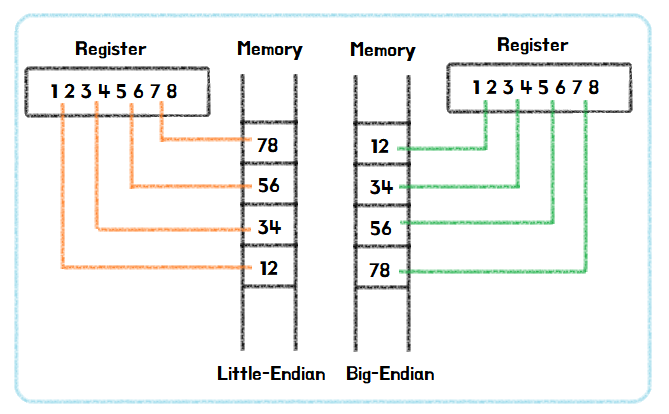
개발자가 상식적으로 생각할때는 당연히 Big Endian이 익숙하고 자연스럽다.
그러면 굳이 왜 Intel과 ARM은 Little Endian을 선택해서 우릴 혼란스럽게 만드는 걸까?
Little Endian도 몇가지 장점이 있다.
만약 해당 바이트의 하위 값을 쓰고자 할때는 하위 바이트가 앞에나온 Little Endian이 유리하다.
또한 가산기에서 덧셈을 하는 방식 중 아래 자리부터 캐리를 올려가며 덧셈하는 방식이 있는데 이 때도 Little Endian이 구현하기 쉽다고 한다.
Endian 방식을 잘 고려해야 하는 상황이 바로 네트워크 통신이다. 만약 Little Endian을 사용하는 호스트가 Big Endian을 사용하는 원격 호스트에게 0x1234를 보낸다고 했을때 Littel Endian이므로 0x3412의 바이트오더로 보내게 된다.
그걸 받는 원격 호스트는 자신의 바이트 오더대로 앞자리 부터 읽을 것이고 0x3412라는 전혀 다른 값으로 인식 한다는 것이다.
단 헷갈리지 말아야 할 점이 있는데, 엔디안으로 인해 적용되는 바이트오더는 하나의 타입 안에서 2바이트 이상의 바이트코드가 들어 있을때의 경우 라는 것이다. (예를 들면 Short 부터가 되겠다.)
만약 char로 이루어진 문자열을 보낸다 할때는 엔디안 변환이 이루어 지지 않는다. char는 1Byte의 타입이고 소켓 전송 특성상 바이트 단위로 보낸 순서대로 붙는다. 하지만 int, short 등 하나의 자료형 안에 여러 바이트가 들어 있는 경우 엔디안에 따라 바이트 오더가 달라지게 되고 문제가 생기는 것이다.
이러한 문제 때문에 네트워크상 전송되는 데이터의 바이트 오더는 무조건 Big Endian으로 하기로 약속을 정해놨다. 엔디안 변환 함수인 htons()는 호스트의 바이트오더를 네트워크 바이트오더(Big Endian 방식)으로 바꿔준다.
그래서 패킷의 헤더상에 붙는 아이피와 포트 번호는 보통 htons(l) 함수를 이용해 바꿔 준 후 보내야 그걸 참조하는 라우터나 L3스위치가 자신들의 방식인 Big Endian으로 읽을 수 있다.
그렇다면 앞으로 숫자 하나 보낼때마다 htons(l)를 사용하고 받을 때마다 ntohs(l)를 사용해 받아야 하는건가?
그렇진 않다. 현재 내가 보는 '윤성우의 열혈 TCP/IP 소켓프로그래밍' 책에서는 페이로드(데이터)부분의 바이트 오더 변환은 자동으로 해준다고 나와있다. 즉 sockaddr_in에 들어가는 IP와 포트번호만 신경써주면 된다는 것이다. 페이로드 데이터는 라이브러리 상에서 헤더를 패킹, 언패킹할때 자동으로 Endian변환이 되지 않을까 생각된다.
'네트워크, 서버 > 소켓,프로토콜' 카테고리의 다른 글
| (소켓,프로토콜)TCP 소켓의 종료 (0) | 2020.10.05 |
|---|---|
| (소켓,프로토콜) UDP소켓 (0) | 2020.09.22 |
| (소켓,프로토콜)소켓 프로토콜 (0) | 2020.07.02 |
| (소켓,프로토콜)Linux와 Windows에서의 소켓 (1) | 2020.06.30 |



